#Python packaging and distribution
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been banned in Indonesia for providing people with access to pornographic content.
Text
Learn how to streamline Python packaging and distribution from code to PyPI! This comprehensive guide by BoTree Technologies covers essential steps, best practices, and tips to create and share your Python packages efficiently. Whether you're a developer looking to share your libraries or a team ensuring seamless distribution, this resource is your go-to for mastering Python packaging. Explore the ins and outs of packaging, versioning, metadata, dependencies, and more. Elevate your Python development process and make your packages accessible to the wider community. Dive into this informative guide and enhance your Python packaging skills today!
0 notes
Text
Good news, I've had a small breakthrough, while figuring out how to distribute the threading code I realized we can easily package dependencies, code and arbitrary files using almost the same methods. Meaning (firstly) portable Python applications in a single file. This will make it easy to distribute applications over PierMesh, though some security considerations will have to be made.
30 notes
·
View notes
Text
hi ive been working on my gag calculator for unm
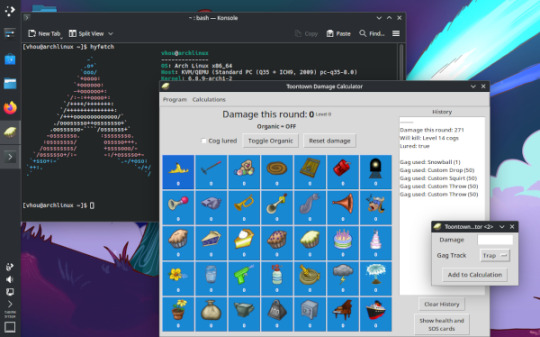
there's a couple big things lots of people will care about, and then a couple big things only a few people, or maybe just me will care about.
the biggest thing the most people will care about is custom gags, i think this is the only gag calculator that allows for users to input a gag with a custom amount of damage, which i think is pretty cool!
ive also started using github actions to build releases rather than my own hardware (since my laptop running windows died and i currently cant otherwise make a windows executable lol) which also allows me to make executables for operating systems besides windows, and throw them in releases.
so i can now make macos executable releases! i cant actually test them myself because i don't have a mac, but in theory i think they should work! one fear is that pyinstaller's automatic codesigning is not good enough and it doesn't let you run the program without turning off security features, which wouldn't look good in the readme LOL
github actions also lets me automatically build and publish the python package versions as well, so those will now be cross platform and update beyond 4.2.0, which is nice. so sorry to the 3 people who use the python package it isn't up to date 😭
the python packages also let you run the command "tt-damage-calculator" in your terminal to open the calculator now instead of "python -m tt_damage_calculator" which i think is pretty cool
ive also been playing with arch linux for the past week or so, and pushed a dev build of the calculator to the AUR, so maybe i'll start using that as another way to distribute the calculator besides pypi and the executables, just in case anyone uses arch.
the entire program was recently recoded into a more object oriented format over the past few months. this is like the fifth major rewrite ive done of the calculator, and hopefully the second to last. i kind of want to drop tk in favor of a nicer gui builder, like qt or something. but that's something for the future.
the latest dev version of the calculator with all this stuff is at https://github.com/Vhou-Atroph/TT-Damage-Calculator/releases/tag/V4.3.0_dev.4 if you like executables, https://github.com/Vhou-Atroph/TT-Damage-Calculator/actions/runs/9149820048 if you like wheels, and https://aur.archlinux.org/packages/tt-damage-calculator if you're an arch user. it has stuff for unm, so it's not really usable on the live server, but it still has some cool features i'm proud of and wanted to talk about lol
14 notes
·
View notes
Text
Several big businesses have published source code that incorporates a software package previously hallucinated by generative AI.
Not only that but someone, having spotted this reoccurring hallucination, had turned that made-up dependency into a real one, which was subsequently downloaded and installed thousands of times by developers as a result of the AI's bad advice, we've learned. If the package was laced with actual malware, rather than being a benign test, the results could have been disastrous.
According to Bar Lanyado, security researcher at Lasso Security, one of the businesses fooled by AI into incorporating the package is Alibaba, which at the time of writing still includes a pip command to download the Python package huggingface-cli in its GraphTranslator installation instructions.
There is a legit huggingface-cli, installed using pip install -U "huggingface_hub[cli]".
But the huggingface-cli distributed via the Python Package Index (PyPI) and required by Alibaba's GraphTranslator – installed using pip install huggingface-cli – is fake, imagined by AI and turned real by Lanyado as an experiment.
He created huggingface-cli in December after seeing it repeatedly hallucinated by generative AI; by February this year, Alibaba was referring to it in GraphTranslator's README instructions rather than the real Hugging Face CLI tool.
5 notes
·
View notes
Text
Intel VTune Profiler For Data Parallel Python Applications

Intel VTune Profiler tutorial
This brief tutorial will show you how to use Intel VTune Profiler to profile the performance of a Python application using the NumPy and Numba example applications.
Analysing Performance in Applications and Systems
For HPC, cloud, IoT, media, storage, and other applications, Intel VTune Profiler optimises system performance, application performance, and system configuration.
Optimise the performance of the entire application not just the accelerated part using the CPU, GPU, and FPGA.
Profile SYCL, C, C++, C#, Fortran, OpenCL code, Python, Google Go, Java,.NET, Assembly, or any combination of languages can be multilingual.
Application or System: Obtain detailed results mapped to source code or coarse-grained system data for a longer time period.
Power: Maximise efficiency without resorting to thermal or power-related throttling.
VTune platform profiler
It has following Features.
Optimisation of Algorithms
Find your code’s “hot spots,” or the sections that take the longest.
Use Flame Graph to see hot code routes and the amount of time spent in each function and with its callees.
Bottlenecks in Microarchitecture and Memory
Use microarchitecture exploration analysis to pinpoint the major hardware problems affecting your application’s performance.
Identify memory-access-related concerns, such as cache misses and difficulty with high bandwidth.
Inductors and XPUs
Improve data transfers and GPU offload schema for SYCL, OpenCL, Microsoft DirectX, or OpenMP offload code. Determine which GPU kernels take the longest to optimise further.
Examine GPU-bound programs for inefficient kernel algorithms or microarchitectural restrictions that may be causing performance problems.
Examine FPGA utilisation and the interactions between CPU and FPGA.
Technical summary: Determine the most time-consuming operations that are executing on the neural processing unit (NPU) and learn how much data is exchanged between the NPU and DDR memory.
In parallelism
Check the threading efficiency of the code. Determine which threading problems are affecting performance.
Examine compute-intensive or throughput HPC programs to determine how well they utilise memory, vectorisation, and the CPU.
Interface and Platform
Find the points in I/O-intensive applications where performance is stalled. Examine the hardware’s ability to handle I/O traffic produced by integrated accelerators or external PCIe devices.
Use System Overview to get a detailed overview of short-term workloads.
Multiple Nodes
Describe the performance characteristics of workloads involving OpenMP and large-scale message passing interfaces (MPI).
Determine any scalability problems and receive suggestions for a thorough investigation.
Intel VTune Profiler
To improve Python performance while using Intel systems, install and utilise the Intel Distribution for Python and Data Parallel Extensions for Python with your applications.
Configure your Python-using VTune Profiler setup.
To find performance issues and areas for improvement, profile three distinct Python application implementations. The pairwise distance calculation algorithm commonly used in machine learning and data analytics will be demonstrated in this article using the NumPy example.
The following packages are used by the three distinct implementations.
Numpy Optimised for Intel
NumPy’s Data Parallel Extension
Extensions for Numba on GPU with Data Parallelism
Python’s NumPy and Data Parallel Extension
By providing optimised heterogeneous computing, Intel Distribution for Python and Intel Data Parallel Extension for Python offer a fantastic and straightforward approach to develop high-performance machine learning (ML) and scientific applications.
Added to the Python Intel Distribution is:
Scalability on PCs, powerful servers, and laptops utilising every CPU core available.
Assistance with the most recent Intel CPU instruction sets.
Accelerating core numerical and machine learning packages with libraries such as the Intel oneAPI Math Kernel Library (oneMKL) and Intel oneAPI Data Analytics Library (oneDAL) allows for near-native performance.
Tools for optimising Python code into instructions with more productivity.
Important Python bindings to help your Python project integrate Intel native tools more easily.
Three core packages make up the Data Parallel Extensions for Python:
The NumPy Data Parallel Extensions (dpnp)
Data Parallel Extensions for Numba, aka numba_dpex
Tensor data structure support, device selection, data allocation on devices, and user-defined data parallel extensions for Python are all provided by the dpctl (Data Parallel Control library).
It is best to obtain insights with comprehensive source code level analysis into compute and memory bottlenecks in order to promptly identify and resolve unanticipated performance difficulties in Machine Learning (ML), Artificial Intelligence ( AI), and other scientific workloads. This may be done with Python-based ML and AI programs as well as C/C++ code using Intel VTune Profiler. The methods for profiling these kinds of Python apps are the main topic of this paper.
Using highly optimised Intel Optimised Numpy and Data Parallel Extension for Python libraries, developers can replace the source lines causing performance loss with the help of Intel VTune Profiler, a sophisticated tool.
Setting up and Installing
1. Install Intel Distribution for Python
2. Create a Python Virtual Environment
python -m venv pyenv
pyenv\Scripts\activate
3. Install Python packages
pip install numpy
pip install dpnp
pip install numba
pip install numba-dpex
pip install pyitt
Make Use of Reference Configuration
The hardware and software components used for the reference example code we use are:
Software Components:
dpnp 0.14.0+189.gfcddad2474
mkl-fft 1.3.8
mkl-random 1.2.4
mkl-service 2.4.0
mkl-umath 0.1.1
numba 0.59.0
numba-dpex 0.21.4
numpy 1.26.4
pyitt 1.1.0
Operating System:
Linux, Ubuntu 22.04.3 LTS
CPU:
Intel Xeon Platinum 8480+
GPU:
Intel Data Center GPU Max 1550
The Example Application for NumPy
Intel will demonstrate how to use Intel VTune Profiler and its Intel Instrumentation and Tracing Technology (ITT) API to optimise a NumPy application step-by-step. The pairwise distance application, a well-liked approach in fields including biology, high performance computing (HPC), machine learning, and geographic data analytics, will be used in this article.
Summary
The three stages of optimisation that we will discuss in this post are summarised as follows:
Step 1: Examining the Intel Optimised Numpy Pairwise Distance Implementation: Here, we’ll attempt to comprehend the obstacles affecting the NumPy implementation’s performance.
Step 2: Profiling Data Parallel Extension for Pairwise Distance NumPy Implementation: We intend to examine the implementation and see whether there is a performance disparity.
Step 3: Profiling Data Parallel Extension for Pairwise Distance Implementation on Numba GPU: Analysing the numba-dpex implementation’s GPU performance
Boost Your Python NumPy Application
Intel has shown how to quickly discover compute and memory bottlenecks in a Python application using Intel VTune Profiler.
Intel VTune Profiler aids in identifying bottlenecks’ root causes and strategies for enhancing application performance.
It can assist in mapping the main bottleneck jobs to the source code/assembly level and displaying the related CPU/GPU time.
Even more comprehensive, developer-friendly profiling results can be obtained by using the Instrumentation and Tracing API (ITT APIs).
Read more on govindhtech.com
#Intel#IntelVTuneProfiler#Python#CPU#GPU#FPGA#Intelsystems#machinelearning#oneMKL#news#technews#technology#technologynews#technologytrends#govindhtech
2 notes
·
View notes
Text
Unlock the World of Data Analysis: Programming Languages for Success!
💡 When it comes to data analysis, choosing the right programming language can make all the difference. Here are some popular languages that empower professionals in this exciting field
https://www.clinicalbiostats.com/
🐍 Python: Known for its versatility, Python offers a robust ecosystem of libraries like Pandas, NumPy, and Matplotlib. It's beginner-friendly and widely used for data manipulation, visualization, and machine learning.
📈 R: Built specifically for statistical analysis, R provides an extensive collection of packages like dplyr, ggplot2, and caret. It excels in data exploration, visualization, and advanced statistical modeling.
🔢 SQL: Structured Query Language (SQL) is essential for working with databases. It allows you to extract, manipulate, and analyze large datasets efficiently, making it a go-to language for data retrieval and management.
💻 Java: Widely used in enterprise-level applications, Java offers powerful libraries like Apache Hadoop and Apache Spark for big data processing. It provides scalability and performance for complex data analysis tasks.
📊 MATLAB: Renowned for its mathematical and numerical computing capabilities, MATLAB is favored in academic and research settings. It excels in data visualization, signal processing, and algorithm development.
🔬 Julia: Known for its speed and ease of use, Julia is gaining popularity in scientific computing and data analysis. Its syntax resembles mathematical notation, making it intuitive for scientists and statisticians.
🌐 Scala: Scala, with its seamless integration with Apache Spark, is a valuable language for distributed data processing and big data analytics. It combines object-oriented and functional programming paradigms.
💪 The key is to choose a language that aligns with your specific goals and preferences. Embrace the power of programming and unleash your potential in the dynamic field of data analysis! 💻📈
#DataAnalysis#ProgrammingLanguages#Python#RStats#SQL#Java#MATLAB#JuliaLang#Scala#DataScience#BigData#CareerOpportunities#biostatistics#onlinelearning#lifesciences#epidemiology#genetics#pythonprogramming#clinicalbiostatistics#datavisualization#clinicaltrials
4 notes
·
View notes
Text
This Week in Rust 510
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
Announcing Rust 1.72.0
Change in Guidance on Committing Lockfiles
Cargo changes how arrays in config are merged
Seeking help for initial Leadership Council initiatives
Leadership Council Membership Changes
Newsletters
This Week in Ars Militaris VIII
Project/Tooling Updates
rust-analyzer changelog #196
The First Stable Release of a Memory Safe sudo Implementation
We're open-sourcing the library that powers 1Password's ability to log in with a passkey
ratatui 0.23.0 is released! (official successor of tui-rs)
Zellij 0.38.0: session-manager, plugin infra, and no more offensive session names
Observations/Thoughts
The fastest WebSocket implementation
Rust Malware Staged on Crates.io
ESP32 Standard Library Embedded Rust: SPI with the MAX7219 LED Dot Matrix
A JVM in Rust part 5 - Executing instructions
Compiling Rust for .NET, using only tea and stubbornness!
Ad-hoc polymorphism erodes type-safety
How to speed up the Rust compiler in August 2023
This isn't the way to speed up Rust compile times
Rust Cryptography Should be Written in Rust
Dependency injection in Axum handlers. A quick tour
Best Rust Web Frameworks to Use in 2023
From tui-rs to Ratatui: 6 Months of Cooking Up Rust TUIs
[video] Rust 1.72.0
[video] Rust 1.72 Release Train
Rust Walkthroughs
[series] Distributed Tracing in Rust, Episode 3: tracing basics
Use Rust in shell scripts
A Simple CRUD API in Rust with Cloudflare Workers, Cloudflare KV, and the Rust Router
[video] base64 crate: code walkthrough
Miscellaneous
Interview with Rust and operating system Developer Andy Python
Leveraging Rust in our high-performance Java database
Rust error message to fix a typo
[video] The Builder Pattern and Typestate Programming - Stefan Baumgartner - Rust Linz January 2023
[video] CI with Rust and Gitlab Selfhosting - Stefan Schindler - Rust Linz July 2023
Crate of the Week
This week's crate is dprint, a fast code formatter that formats Markdown, TypeScript, JavaScript, JSON, TOML and many other types natively via Wasm plugins.
Thanks to Martin Geisler for the suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Hyperswitch - add domain type for client secret
Hyperswitch - deserialization error exposes sensitive values in the logs
Hyperswitch - move redis key creation to a common module
mdbook-i18n-helpers - Write tool which can convert translated files back to PO
mdbook-i18n-helpers - Package a language selector
mdbook-i18n-helpers - Add links between translations
Comprehensive Rust - Link to correct line when editing a translation
Comprehensive Rust - Track the number of times the redirect pages are visited
RustQuant - Jacobian and Hessian matrices support.
RustQuant - improve Graphviz plotting of autodiff computational graphs.
RustQuant - bond pricing implementation.
RustQuant - implement cap/floor pricers.
RustQuant - Implement Asian option pricers.
RustQuant - Implement American option pricers.
release-plz - add ability to mark Gitea/GitHub release as draft
zerocopy - CI step "Set toolchain version" is flaky due to network timeouts
zerocopy - Implement traits for tuple types (and maybe other container types?)
zerocopy - Prevent panics statically
zerocopy - Add positive and negative trait impl tests for SIMD types
zerocopy - Inline many trait methods (in zerocopy and in derive-generated code)
datatest-stable - Fix quadratic performance with nextest
Ockam - Use a user-friendly name for the shared services to show it in the tray menu
Ockam - Rename the Port to Address and support such format
Ockam - Ockam CLI should gracefully handle invalid state when initializing
css-inline - Update cssparser & selectors
css-inline - Non-blocking stylesheet resolving
css-inline - Optionally remove all class attributes
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
366 pull requests were merged in the last week
reassign sparc-unknown-none-elf to tier 3
wasi: round up the size for aligned_alloc
allow MaybeUninit in input and output of inline assembly
allow explicit #[repr(Rust)]
fix CFI: f32 and f64 are encoded incorrectly for cross-language CFI
add suggestion for some #[deprecated] items
add an (perma-)unstable option to disable vtable vptr
add comment to the push_trailing function
add note when matching on tuples/ADTs containing non-exhaustive types
add support for ptr::writes for the invalid_reference_casting lint
allow overwriting ExpnId for concurrent decoding
avoid duplicate large_assignments lints
contents of reachable statics is reachable
do not emit invalid suggestion in E0191 when spans overlap
do not forget to pass DWARF fragment information to LLVM
ensure that THIR unsafety check is done before stealing it
emit a proper diagnostic message for unstable lints passed from CLI
fix races conditions with SyntaxContext decoding
fix waiting on a query that panicked
improve note for the invalid_reference_casting lint
include compiler flags when you break rust;
load include_bytes! directly into an Lrc
make Sharded an enum and specialize it for the single thread case
make rustc_on_unimplemented std-agnostic for alloc::rc
more precisely detect cycle errors from type_of on opaque
point at type parameter that introduced unmet bound instead of full HIR node
record allocation spans inside force_allocation
suggest mutable borrow on read only for-loop that should be mutable
tweak output of to_pretty_impl_header involving only anon lifetimes
use the same DISubprogram for each instance of the same inlined function within a caller
walk through full path in point_at_path_if_possible
warn on elided lifetimes in associated constants (ELIDED_LIFETIMES_IN_ASSOCIATED_CONSTANT)
make RPITITs capture all in-scope lifetimes
add stable for Constant in smir
add generics_of to smir
add smir predicates_of
treat StatementKind::Coverage as completely opaque for SMIR purposes
do not convert copies of packed projections to moves
don't do intra-pass validation on MIR shims
MIR validation: reject in-place argument/return for packed fields
disable MIR SROA optimization by default
miri: automatically start and stop josh in rustc-pull/push
miri: fix some bad regex capture group references in test normalization
stop emitting non-power-of-two vectors in (non-portable-SIMD) codegen
resolve: stop creating NameBindings on every use, create them once per definition instead
fix a pthread_t handle leak
when terminating during unwinding, show the reason why
avoid triple-backtrace due to panic-during-cleanup
add additional float constants
add ability to spawn Windows process with Proc Thread Attributes | Take 2
fix implementation of Duration::checked_div
hashbrown: allow serializing HashMaps that use a custom allocator
hashbrown: change & to &mut where applicable
hashbrown: simplify Clone by removing redundant guards
regex-automata: fix incorrect use of Aho-Corasick's "standard" semantics
cargo: Very preliminary MSRV resolver support
cargo: Use a more compact relative-time format
cargo: Improve TOML parse errors
cargo: add support for target.'cfg(..)'.linker
cargo: config: merge lists in precedence order
cargo: create dedicated unstable flag for asymmetric-token
cargo: set MSRV for internal packages
cargo: improve deserialization errors of untagged enums
cargo: improve resolver version mismatch warning
cargo: stabilize --keep-going
cargo: support dependencies from registries for artifact dependencies, take 2
cargo: use AND search when having multiple terms
rustdoc: add unstable --no-html-source flag
rustdoc: rename typedef to type alias
rustdoc: use unicode-aware checks for redundant explicit link fastpath
clippy: new lint: implied_bounds_in_impls
clippy: new lint: reserve_after_initialization
clippy: arithmetic_side_effects: detect division by zero for Wrapping and Saturating
clippy: if_then_some_else_none: look into local initializers for early returns
clippy: iter_overeager_cloned: detect .cloned().all() and .cloned().any()
clippy: unnecessary_unwrap: lint on .as_ref().unwrap()
clippy: allow trait alias DefIds in implements_trait_with_env_from_iter
clippy: fix "derivable_impls: attributes are ignored"
clippy: fix tuple_array_conversions lint on nightly
clippy: skip float_cmp check if lhs is a custom type
rust-analyzer: diagnostics for 'while let' loop with label in condition
rust-analyzer: respect #[allow(unused_braces)]
Rust Compiler Performance Triage
A fairly quiet week, with improvements exceeding a small scattering of regressions. Memory usage and artifact size held fairly steady across the week, with no regressions or improvements.
Triage done by @simulacrum. Revision range: d4a881e..cedbe5c
2 Regressions, 3 Improvements, 2 Mixed; 0 of them in rollups 108 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
Create a Testing sub-team
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Stabilize PATH option for --print KIND=PATH
[disposition: merge] Add alignment to the NPO guarantee
New and Updated RFCs
[new] Special-cased performance improvement for Iterator::sum on Range<u*> and RangeInclusive<u*>
[new] Cargo Check T-lang Policy
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2023-08-30 - 2023-09-27 🦀
Virtual
2023-09-05 | Virtual (Buffalo, NY, US) | Buffalo Rust Meetup
Buffalo Rust User Group, First Tuesdays
2023-09-05 | Virtual (Munich, DE) | Rust Munich
Rust Munich 2023 / 4 - hybrid
2023-09-06 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2023-09-12 - 2023-09-15 | Virtual (Albuquerque, NM, US) | RustConf
RustConf 2023
2023-09-12 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2023-09-13 | Virtual (Boulder, CO, US) | Boulder Elixir and Rust
Monthly Meetup
2023-09-13 | Virtual (Cardiff, UK)| Rust and C++ Cardiff
The unreasonable power of combinator APIs
2023-09-14 | Virtual (Nuremberg, DE) | Rust Nuremberg
Rust Nürnberg online
2023-09-20 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2023-09-21 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2023-09-21 | Lehi, UT, US | Utah Rust
Real Time Multiplayer Game Server in Rust
2023-09-21 | Virtual (Linz, AT) | Rust Linz
Rust Meetup Linz - 33rd Edition
2023-09-25 | Virtual (Dublin, IE) | Rust Dublin
How we built the SurrealDB Python client in Rust.
Asia
2023-09-06 | Tel Aviv, IL | Rust TLV
RustTLV @ Final - September Edition
Europe
2023-08-30 | Copenhagen, DK | Copenhagen Rust Community
Rust metup #39 sponsored by Fermyon
2023-08-31 | Augsburg, DE | Rust Meetup Augsburg
Augsburg Rust Meetup #2
2023-09-05 | Munich, DE + Virtual | Rust Munich
Rust Munich 2023 / 4 - hybrid
2023-09-14 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup at Browns
2023-09-19 | Augsburg, DE | Rust - Modern Systems Programming in Leipzig
Logging and tracing in Rust
2023-09-20 | Aarhus, DK | Rust Aarhus
Rust Aarhus - Rust and Talk at Concordium
2023-09-21 | Bern, CH | Rust Bern
Third Rust Bern Meetup
North America
2023-09-05 | Chicago, IL, US | Deep Dish Rust
Rust Happy Hour
2023-09-06 | Bellevue, WA, US | The Linux Foundation
Rust Global
2023-09-12 - 2023-09-15 | Albuquerque, NM, US + Virtual | RustConf
RustConf 2023
2023-09-12 | New York, NY, US | Rust NYC
A Panel Discussion on Thriving in a Rust-Driven Workplace
2023-09-12 | Minneapolis, MN, US | Minneapolis Rust Meetup
Minneapolis Rust Meetup Happy Hour
2023-09-14 | Seattle, WA, US | Seattle Rust User Group Meetup
Seattle Rust User Group - August Meetup
2023-09-19 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2023-09-21 | Nashville, TN, US | Music City Rust Developers
Rust on the web! Get started with Leptos
2023-09-26 | Pasadena, CA, US | Pasadena Thursday Go/Rust
Monthly Rust group
2023-09-27 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
Oceania
2023-09-13 | Perth, WA, AU | Rust Perth
Rust Meetup 2: Lunch & Learn
2023-09-19 | Christchurch, NZ | Christchurch Rust Meetup Group
Christchurch Rust meetup meeting
2023-09-26 | Canberra, ACT, AU | Rust Canberra
September Meetup
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
In [other languages], I could end up chasing silly bugs and waste time debugging and tracing to find that I made a typo or ran into a language quirk that gave me an unexpected nil pointer. That situation is almost non-existent in Rust, it's just me and the problem. Rust is honest and upfront about its quirks and will yell at you about it before you have a hard to find bug in production.
– dannersy on Hacker News
Thanks to Kyle Strand for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
0 notes
Text
Microsoft Scrimble Framework also comes in like 3 different variants that have wildly varying interfaces based on if they're built for .NET, .NET core 2.0 or .NET core 2.1. Only the .NET core 2.1 version is available via nuget, the rest have to be compiled from some guy's fork of Microsoft's git repository (you can't use the original because it's been marked as an archive, and the Microsoft team has moved over to committing to that guy's fork instead).
You're also forgetting pysqueeb-it, an insane combination of python packages that's only distributed as a dockerfile and builds into a monolithic single-command docker entrypoint. Thankfully all of this is pulled for you when you try to build the docker image but unfortunately the package also requires Torch for some inexplicable reason (i guess we're squeebing with tensors now?) so get ready to wait for an hour while pip pulls that alongside the other 200 packages in requirements.txt. Make sure you install version==2.1.3 and replace the relevant lines in the .env file with your public keys before the build, otherwise you get to do all this again in 2 hours (being a docker build, pip can't cache packages so it's going to pull torch and everything else again every single time).
every software is like. your mission-critical app requires you to use the scrimble protocol to squeeb some snorble files for sprongle expressions. do you use:
libsnorble-2-dev, a C library that the author only distributes as source code and therefore must be compiled from source using CMake
Squeeb.js, which sort of has most of the features you want, but requires about a gigabyte of Node dependencies and has only been in development for eight months and has 4.7k open issues on Github
Squeeh.js, a typosquatting trojan that uses your GPU to mine crypto if you install it by mistake
Sprongloxide, a Rust crate beloved by its fanatical userbase, which has been in version 0.9.* for about four years, and is actually just a thin wrapper for libsnorble-2-dev
GNU Scrimble, a GPLv3-licensed command-line tool maintained by the Free Software Foundation, which has over a hundred different flags, and also comes with an integrated Lisp interpreter for scripting, and also a TUI-based Pong implementation as an "easter egg", and also supports CSV, XML, JSON, PDF, XLSX, and even HTML files, but does not actually come with support for squeebing snorble files for ideological reasons. it does have a boomeresque drawing of a grinning meerkat as its logo, though
Microsoft Scrimble Framework Core, a .NET library that has all the features you need and more, but costs $399 anually and comes with a proprietary licensing agreement that grants Microsoft the right to tattoo advertisements on the inside of your eyelids
snorblite, a full-featured Perl module which is entirely developed and maintained by a single guy who is completely insane and constantly makes blog posts about how much he hates the ATF and the "woke mind-virus", but everyone uses it because it has all the features you need and is distributed under the MIT license
Google Squeebular (deprecated since 2017)
7K notes
·
View notes
Text
The Best Open-Source Tools for Data Science in 2025

Data science in 2025 is thriving, driven by a robust ecosystem of open-source tools that empower professionals to extract insights, build predictive models, and deploy data-driven solutions at scale. This year, the landscape is more dynamic than ever, with established favorites and emerging contenders shaping how data scientists work. Here’s an in-depth look at the best open-source tools that are defining data science in 2025.
1. Python: The Universal Language of Data Science
Python remains the cornerstone of data science. Its intuitive syntax, extensive libraries, and active community make it the go-to language for everything from data wrangling to deep learning. Libraries such as NumPy and Pandas streamline numerical computations and data manipulation, while scikit-learn is the gold standard for classical machine learning tasks.
NumPy: Efficient array operations and mathematical functions.
Pandas: Powerful data structures (DataFrames) for cleaning, transforming, and analyzing structured data.
scikit-learn: Comprehensive suite for classification, regression, clustering, and model evaluation.
Python’s popularity is reflected in the 2025 Stack Overflow Developer Survey, with 53% of developers using it for data projects.
2. R and RStudio: Statistical Powerhouses
R continues to shine in academia and industries where statistical rigor is paramount. The RStudio IDE enhances productivity with features for scripting, debugging, and visualization. R’s package ecosystem—especially tidyverse for data manipulation and ggplot2 for visualization—remains unmatched for statistical analysis and custom plotting.
Shiny: Build interactive web applications directly from R.
CRAN: Over 18,000 packages for every conceivable statistical need.
R is favored by 36% of users, especially for advanced analytics and research.
3. Jupyter Notebooks and JupyterLab: Interactive Exploration
Jupyter Notebooks are indispensable for prototyping, sharing, and documenting data science workflows. They support live code (Python, R, Julia, and more), visualizations, and narrative text in a single document. JupyterLab, the next-generation interface, offers enhanced collaboration and modularity.
Over 15 million notebooks hosted as of 2025, with 80% of data analysts using them regularly.
4. Apache Spark: Big Data at Lightning Speed
As data volumes grow, Apache Spark stands out for its ability to process massive datasets rapidly, both in batch and real-time. Spark’s distributed architecture, support for SQL, machine learning (MLlib), and compatibility with Python, R, Scala, and Java make it a staple for big data analytics.
65% increase in Spark adoption since 2023, reflecting its scalability and performance.
5. TensorFlow and PyTorch: Deep Learning Titans
For machine learning and AI, TensorFlow and PyTorch dominate. Both offer flexible APIs for building and training neural networks, with strong community support and integration with cloud platforms.
TensorFlow: Preferred for production-grade models and scalability; used by over 33% of ML professionals.
PyTorch: Valued for its dynamic computation graph and ease of experimentation, especially in research settings.
6. Data Visualization: Plotly, D3.js, and Apache Superset
Effective data storytelling relies on compelling visualizations:
Plotly: Python-based, supports interactive and publication-quality charts; easy for both static and dynamic visualizations.
D3.js: JavaScript library for highly customizable, web-based visualizations; ideal for specialists seeking full control.
Apache Superset: Open-source dashboarding platform for interactive, scalable visual analytics; increasingly adopted for enterprise BI.
Tableau Public, though not fully open-source, is also popular for sharing interactive visualizations with a broad audience.
7. Pandas: The Data Wrangling Workhorse
Pandas remains the backbone of data manipulation in Python, powering up to 90% of data wrangling tasks. Its DataFrame structure simplifies complex operations, making it essential for cleaning, transforming, and analyzing large datasets.
8. Scikit-learn: Machine Learning Made Simple
scikit-learn is the default choice for classical machine learning. Its consistent API, extensive documentation, and wide range of algorithms make it ideal for tasks such as classification, regression, clustering, and model validation.
9. Apache Airflow: Workflow Orchestration
As data pipelines become more complex, Apache Airflow has emerged as the go-to tool for workflow automation and orchestration. Its user-friendly interface and scalability have driven a 35% surge in adoption among data engineers in the past year.
10. MLflow: Model Management and Experiment Tracking
MLflow streamlines the machine learning lifecycle, offering tools for experiment tracking, model packaging, and deployment. Over 60% of ML engineers use MLflow for its integration capabilities and ease of use in production environments.
11. Docker and Kubernetes: Reproducibility and Scalability
Containerization with Docker and orchestration via Kubernetes ensure that data science applications run consistently across environments. These tools are now standard for deploying models and scaling data-driven services in production.
12. Emerging Contenders: Streamlit and More
Streamlit: Rapidly build and deploy interactive data apps with minimal code, gaining popularity for internal dashboards and quick prototypes.
Redash: SQL-based visualization and dashboarding tool, ideal for teams needing quick insights from databases.
Kibana: Real-time data exploration and monitoring, especially for log analytics and anomaly detection.
Conclusion: The Open-Source Advantage in 2025
Open-source tools continue to drive innovation in data science, making advanced analytics accessible, scalable, and collaborative. Mastery of these tools is not just a technical advantage—it’s essential for staying competitive in a rapidly evolving field. Whether you’re a beginner or a seasoned professional, leveraging this ecosystem will unlock new possibilities and accelerate your journey from raw data to actionable insight.
The future of data science is open, and in 2025, these tools are your ticket to building smarter, faster, and more impactful solutions.
#python#r#rstudio#jupyternotebook#jupyterlab#apachespark#tensorflow#pytorch#plotly#d3js#apachesuperset#pandas#scikitlearn#apacheairflow#mlflow#docker#kubernetes#streamlit#redash#kibana#nschool academy#datascience
0 notes
Text
Unlock Trading Potential: Alltick Stock API Leads the New Era of Market Data
In the fast-paced financial battlefield, every data fluctuation could be the key to profitability. While traditional data interfaces still deliver information with second-level delays, the Alltick Stock API has already achieved nanosecond-level response times, precisely presenting the pulse of global markets to your trading terminal. Whether it's the split-second decisions of high-frequency trading or the in-depth analysis of long-term investments, Alltick is redefining market data services with disruptive technology.
Why is the Alltick Stock API the strategic choice for traders?
Lightning-Fast Response, Seize the Initiative Alltick's distributed data centers are directly connected to global exchanges, compressing real-time market data delays from the New York Stock Exchange and NASDAQ to an astonishing 1.2 milliseconds. During the sharp volatility following Amazon's earnings release, trading teams using the Alltick API were able to capture a 0.8% price fluctuation window ahead of users on ordinary platforms, positioning for profits before institutional investors could react.
Global Coverage, All-Inclusive From Wall Street blue chips to Hong Kong tech stocks, from Frankfurt bond markets to Tokyo forex trading, Alltick integrates data resources from over 80 global exchanges. Emerging market enthusiasts can simultaneously access real-time data from Brazil's B3 and India's NSE, eliminating information barriers for cross-border investments and truly expanding your trading horizon worldwide.
Smart Adaptation, Hassle-Free Development Featuring a unique multi-protocol adaptive framework, Alltick supports 12 mainstream programming languages, including Python, Java, and Go. Beginner developers can quickly integrate using the visual interface generator, while seasoned quant teams can leverage the C++ underlying library for microsecond-level responses. With an automatic fault-tolerance mechanism, Alltick ensured a 99.998% data transmission integrity rate during extreme market conditions at the London Metal Exchange in 2024.
Elastic Scaling, Ready for Anything Designed specifically for high-frequency trading, the dynamic load-balancing system can stably handle 2 million data requests per second during S&P 500 index futures delivery days. Whether you're an individual strategy developer or a multi-billion-dollar institution, you'll enjoy consistently smooth performance.
Transparent Pricing, Flexible Options Offering tiered subscription plans, individual traders can start with a basic package at just $49 per month for NYSE Level 1 real-time data, while professional institutions can customize enterprise solutions including NASDAQ TotalView depth data at 60% of the cost of traditional providers.
Register now with Alltick

0 notes
Text
Python Packaging and Distribution: From Code to PyPI
"Unlock the secrets of Python packaging and distribution in this informative Medium article by Codex. Delve into the comprehensive journey from code to PyPI, understanding the vital steps and best practices involved. Gain insights into packaging your Python projects effectively and distributing them seamlessly, enabling a wider audience to access and utilize your software."
0 notes
Text
Made a repository for Daisy so I can start making that it's own library and use it to experiment with building whls so that later on I can distribute it along with PierMesh as Python packages
If you can't read it for any reason the description of Daisy is "Lightweight msgpack based schemaless local and distributed database". It's something I've been working on in tandem with PierMesh since I don't like the resource usage and inflexibility of working with most database systems
12 notes
·
View notes
Text
What Is Anaconda Distribution Used For Analytics?
Anaconda Distribution is a popular open-source platform designed for data science, machine learning, and large-scale data analytics using Python and R. It simplifies package management and deployment by bundling more than 1,500 packages specifically curated for scientific computing, statistical analysis, and predictive modeling. With Anaconda, users can easily install powerful libraries like NumPy, pandas, scikit-learn, TensorFlow, and Matplotlib without worrying about dependency conflicts.
Anaconda includes Conda, its package and environment manager, which allows users to create isolated environments to manage different project dependencies efficiently. This is especially useful in analytics workflows where version control and reproducibility are crucial. In addition, Anaconda comes with Jupyter Notebook, a widely used tool for interactive data analysis, visualization, and documentation.
The platform is ideal for beginners and professionals alike, providing a complete ecosystem for developing and deploying analytics-driven applications. Its user-friendly interface and community support make it a preferred choice for those entering the world of data.
Whether you're exploring data, building models, or visualizing insights, Anaconda streamlines your analytics pipeline with minimal setup.
To get started effectively, consider enrolling in a Python course for beginners to understand how to use Anaconda proficiently.
0 notes
Text
Driving Innovation with AWS Cloud Development Tools
Amazon Web Services (AWS) has established itself as a leader in cloud computing, providing businesses with a comprehensive suite of services to build, deploy, and manage applications at scale. Among its most impactful offerings are AWS cloud development tools, which enable developers to optimize workflows, automate processes, and accelerate innovation. These tools are indispensable for creating scalable, secure, and reliable cloud-native applications across various industries.

The Importance of AWS Cloud Development Tools
Modern application development demands agility, automation, and seamless collaboration. AWS cloud development tools deliver the infrastructure, services, and integrations required to support the entire software development lifecycle (SDLC)—from coding and testing to deployment and monitoring. Whether catering to startups or large enterprises, these tools reduce manual effort, expedite releases, and uphold best practices in DevOps and cloud-native development.
Key AWS Development Tools
Here is an overview of some widely utilized AWS cloud development tools and their core functionalities:
1. AWS Cloud9
AWS Cloud9 is a cloud-based integrated development environment (IDE) that enables developers to write, run, and debug code directly in their browser. Pre-configured with essential tools, it supports multiple programming languages such as JavaScript, Python, and PHP. By eliminating the need for local development environments, Cloud9 facilitates real-time collaboration and streamlines workflows.
2. AWS CodeCommit
AWS CodeCommit is a fully managed source control service designed to securely host Git-based repositories. It offers features such as version control, fine-grained access management through AWS Identity and Access Management (IAM), and seamless integration with other AWS services, making it a robust option for collaborative development.
3. AWS CodeBuild
AWS CodeBuild automates key development tasks, including compiling source code, running tests, and producing deployment-ready packages. This fully managed service removes the need to maintain build servers, automatically scales resources, and integrates with CodePipeline along with other CI/CD tools, streamlining the build process.
4. AWS CodeDeploy
AWS CodeDeploy automates the deployment of code to Amazon EC2 instances, AWS Lambda, and even on-premises servers. By minimizing downtime, providing deployment tracking, and ensuring safe rollbacks in case of issues, CodeDeploy simplifies and secures the deployment process.
5. AWS CodePipeline
AWS CodePipeline is a fully managed continuous integration and continuous delivery (CI/CD) service that automates the build, test, and deployment stages of the software development lifecycle. It supports integration with third-party tools, such as GitHub and Jenkins, to provide enhanced flexibility and seamless workflows.
6. AWS CDK (Cloud Development Kit)
The AWS Cloud Development Kit allows developers to define cloud infrastructure using familiar programming languages including TypeScript, Python, Java, and C#. By simplifying Infrastructure as Code (IaC), AWS CDK makes provisioning AWS resources more intuitive and easier to maintain.
7. AWS X-Ray
AWS X-Ray assists developers in analyzing and debugging distributed applications by offering comprehensive insights into request behavior, error rates, and system performance bottlenecks. This tool is particularly valuable for applications leveraging microservices-based architectures.
Benefits of Using AWS Development Tools
Scalability: Effortlessly scale development and deployment operations to align with the growth of your applications.
Efficiency: Accelerate the software development lifecycle with automation and integrated workflows.
Security: Utilize built-in security features and IAM controls to safeguard your code and infrastructure.
Cost-Effectiveness: Optimize resources and leverage pay-as-you-go pricing to manage costs effectively.
Innovation: Focus on developing innovative features and solutions without the burden of managing infrastructure.
Conclusion
AWS development tools offer a robust, flexible, and secure foundation for building modern cloud-native applications. Covering every stage of development, from coding to deployment and monitoring, these tools empower organizations to innovate confidently, deliver software faster, and maintain a competitive edge in today’s dynamic digital environment. By leveraging this comprehensive toolset, businesses can streamline operations and enhance their ability to meet evolving challenges with agility.
0 notes
Text
Why Ubuntu is the Perfect Gateway into the Linux World

Linux can feel like a daunting frontier for newcomers. Its reputation for complexity and command-line wizardry often scares off those curious about open-source operating systems. But there’s a friendly entry point that makes the transition smooth and welcoming: Ubuntu. Known for its accessibility and robust community, Ubuntu is the perfect gateway into the Linux world.
This article explores why Ubuntu stands out as the ideal starting point for anyone looking to dive into Linux, covering its user-friendly design, vast software ecosystem, strong community support, and versatility across devices.
A User-Friendly Design That Eases the Learning Curve

Stepping into Linux can feel like learning a new language, but Ubuntu makes it as approachable as a casual conversation. This is why Ubuntu is the perfect gateway into the Linux world: it prioritizes simplicity over complexity. Unlike some Linux distributions that demand technical know-how from the get-go, Ubuntu’s graphical interface, known as GNOME by default, feels familiar to anyone who’s used Windows or macOS. The desktop is clean, intuitive, and packed with thoughtful touches, like a dock for quick app access and a search bar that finds files or settings in seconds.
New users don’t need to wrestle with the terminal to get started. Installing Ubuntu is straightforward, with a guided setup that walks you through partitioning drives and configuring settings. Once installed, the system feels polished and responsive. You can tweak wallpapers, arrange icons, or adjust settings without diving into config files. For those nervous about leaving their comfort zone, Ubuntu’s design bridges the gap between proprietary systems and the Linux world, reinforcing why Ubuntu is the perfect gateway into the Linux world.
It’s not just about looks. Ubuntu’s default apps, like Firefox for browsing, LibreOffice for productivity, and Rhythmbox for music, are pre-installed and ready to go. This means you can hit the ground running without needing to hunt for software. For anyone worried about Linux being “too technical,” Ubuntu proves you can explore open-source without a steep learning curve.
A Vast Software Ecosystem at Your Fingertips
One of Ubuntu’s biggest strengths is its access to a massive library of software, making it a playground for both beginners and seasoned users. The Ubuntu Software Center is a one-stop shop where you can browse, install, and update thousands of applications with a single click. Whether you need a video editor, a code editor, or a game to unwind, Ubuntu has you covered.
Here’s why the software ecosystem makes Ubuntu the perfect gateway into the Linux world:
Snap and Flatpak Support: Ubuntu embraces modern packaging formats like Snap and Flatpak, ensuring you get the latest versions of apps like Slack, Spotify, or VS Code. These formats simplify installation and updates, even for proprietary software.
Debian Roots: Built on Debian, Ubuntu inherits a vast repository of packages accessible via the APT package manager. This gives users access to a wide range of tools, from server software to niche utilities.
Cross-Platform Compatibility: Many apps available on Ubuntu have versions for Windows or macOS, making the switch less jarring. For example, GIMP (a Photoshop alternative) or Blender (for 3D modeling) work similarly across platforms.
This ecosystem empowers users to experiment without feeling overwhelmed. Want to try coding? Install Python or Java with a single command. Need a creative suite? Grab Krita or Inkscape from the Software Center. Ubuntu’s software availability ensures you can tailor your system to your needs, whether you’re a student, developer, or casual user.
A Supportive Community That Has Your Back
Linux can seem intimidating when you hit a snag, but Ubuntu’s community makes troubleshooting feel like a group effort. With millions of users worldwide, Ubuntu boasts one of the largest and most active communities in the Linux world. Whether you’re stuck on a driver issue or curious about customizing your desktop, help is never far away.
The community shines through in several ways:
Forums and Q&A Sites: The Ubuntu Forums and Ask Ubuntu (part of Stack Exchange) are treasure troves of advice. Search for your issue, and chances are someone’s already solved it. If not, post a question, and friendly users will chime in.
Tutorials and Documentation: Ubuntu’s official documentation is clear and beginner-friendly, covering everything from installation to advanced tweaks. Countless blogs and YouTube channels also offer step-by-step guides tailored to new users.
Local User Groups: Many cities have Ubuntu or Linux user groups where enthusiasts meet to share tips and troubleshoot together. These groups make the Linux world feel less like a solo journey and more like a shared adventure.
This support network is a game-changer for newcomers. Instead of feeling lost in a sea of terminal commands, you’re backed by a global community eager to help. It’s like having a knowledgeable friend on speed dial, ready to guide you through any hiccup.
Versatility Across Devices and Use Cases

Ubuntu’s flexibility is another reason it’s the perfect gateway into the Linux world. Whether you’re reviving an old laptop, setting up a home server, or building a developer workstation, Ubuntu adapts to your needs. It runs on everything from low-spec netbooks to high-end workstations, making it a go-to choice for diverse hardware.
For casual users, Ubuntu’s lightweight editions, like Xubuntu or Lubuntu, breathe new life into aging machines. These variants use less resource-hungry desktops while retaining Ubuntu’s core features. Developers love Ubuntu for its robust tools, such as Docker, Kubernetes, and Git, preconfigured for coding environments. Even gamers are finding Ubuntu increasingly viable, thanks to Steam’s Proton and Wine for running Windows games.
Beyond desktops, Ubuntu powers servers, cloud infrastructure, and even IoT devices. Companies like Canonical (Ubuntu’s developer) ensure regular updates and long-term support (LTS) releases, which are stable for five years. This versatility means you can start with Ubuntu on a personal laptop and later explore its server or cloud capabilities without switching distributions.
The ability to customize Ubuntu is a bonus. Want a macOS-like look? Install a theme. Prefer a Windows vibe? Tweak the layout. This adaptability lets users experiment with Linux’s possibilities while staying in a familiar environment. Ubuntu’s balance of stability and flexibility makes it a launching pad for exploring the broader Linux ecosystem.
Conclusion
Ubuntu stands out as the ideal entry point for anyone curious about Linux. Its user-friendly design welcomes beginners with a familiar interface and straightforward setup. The vast software ecosystem ensures you have the tools you need, from creative apps to developer suites.
A supportive community is there to guide you through challenges, making the Linux world feel less intimidating. And with its versatility across devices and use cases, Ubuntu grows with you as your skills and needs evolve. For anyone looking to dip their toes into open-source waters, Ubuntu is the perfect gateway into the Linux world, a friendly, flexible, and powerful starting point for an exciting journey.
#WhyUbuntuisthePerfectGatewayintotheLinuxWorld#CommonLinuxMythsBusted:WhatNewUsersShouldReallyExpect
1 note
·
View note
Text
Agent Communication Protocol: Vision For AI Agent Ecosystems

Agent Communication Protocol IBM
IBM released its Agent Communication Protocol (ACP), an open standard for connecting and cooperating AI agents built on different frameworks and technology stacks. IBM thinks Agent Communication Protocol, a basic layer for interoperability, will become the “HTTP of agent communication,” enabling AI bots a standard language to do complex real-world tasks.
Since agents often operate as “islands” in the current AI ecosystem, the protocol, announced on May 28, 2025, addresses a fundamental issue. Custom integrations, which are expensive, fragile, and hard to scale, are needed to connect these agents.
Every integration is expensive duct tape without a standard. IBM's Agent Communication Protocol aims to eliminate these connections by offering a single interface for agents produced with BeeAI, LangChain, CrewAI, or custom code.
ACP underpins BeeAI, an open-source platform for locating, executing, and building AI agents. IBM gave BeeAI to the charity Linux Foundation in March. Open governance provides transparency and community-driven progress for Agent Communication Protocol and BeeAI. Developers can adopt and improve the standard without being tied to one vendor.
The design of Agent Communication Protocol aimed to improve Anthropic's Model Context Protocol (MCP). MCP has become the standard for agents to access external data and resources. ACP connects agents directly, while MCP connects them to databases and APIs. BeeAI and other multi-agent orchestration systems can leverage ACP and MCP.
IBM Research product manager Jenna Winkler stressed the importance of both protocols for real-world AI expansion. Two agents simultaneously acquire market data and simulate using MCP. They compare their results and give a proposal using Agent Communication Protocol.
Agent Communication Protocol is a RESTful HTTP-based protocol that supports synchronous and asynchronous agent interactions. Since it follows HTTP conventions, this architecture is easier to use and integrate into production systems than protocols that use more complicated communication methods. In comparison, MCP uses JSON-RPC.
Developers can directly communicate with agents using curl, Postman, or a web browser, making Agent Communication Protocol easy to use. Python and TypeScript SDKs are convenient, but a specialised SDK is not necessary.
ACP simplifies offline discovery by letting agents include information in distribution packages. This allows agents to be located in secure, disconnected, or scale-to-zero settings. Agent Communication Protocol's asynchronous architecture is ideal for long workloads, although it offers synchronous communication for easy use cases and testing.
Agent Communication Protocol grants multi-agent system architects more design possibilities beyond technology. It goes beyond the traditional “manager” structure, where one “boss” agent coordinates. ACP lets agents talk and assign jobs without a mediator. Peer-to-peer capacity is crucial for internal and external agent interactions.
Kate Blair, IBM Research director of product incubation, said either agent can contact or assign a job. She described a triage agent who answers consumer questions and sends the history and interaction to the relevant service agent so they can address the ticket independently.
IBM Research showed an early ACP version. Soon after, Google introduced A2A, its agent-to-agent protocol. Blair expects more adjustments as they are tested in real life, and he believes multiple agent methods can be used in the early phases despite new rules.
ACP fosters developer participation and is community-led. Monthly open community calls and an active GitHub discussion section ensure community members always have jobs to offer.
#AgentCommunicationProtocol#BeeAI#ACP#IBMAgentCommunicationProtocol#AgentCommunicationProtocolACP#ModelContextProtocol#technology#technews#technologynews#news#govindhtech
0 notes